Content tagged EN
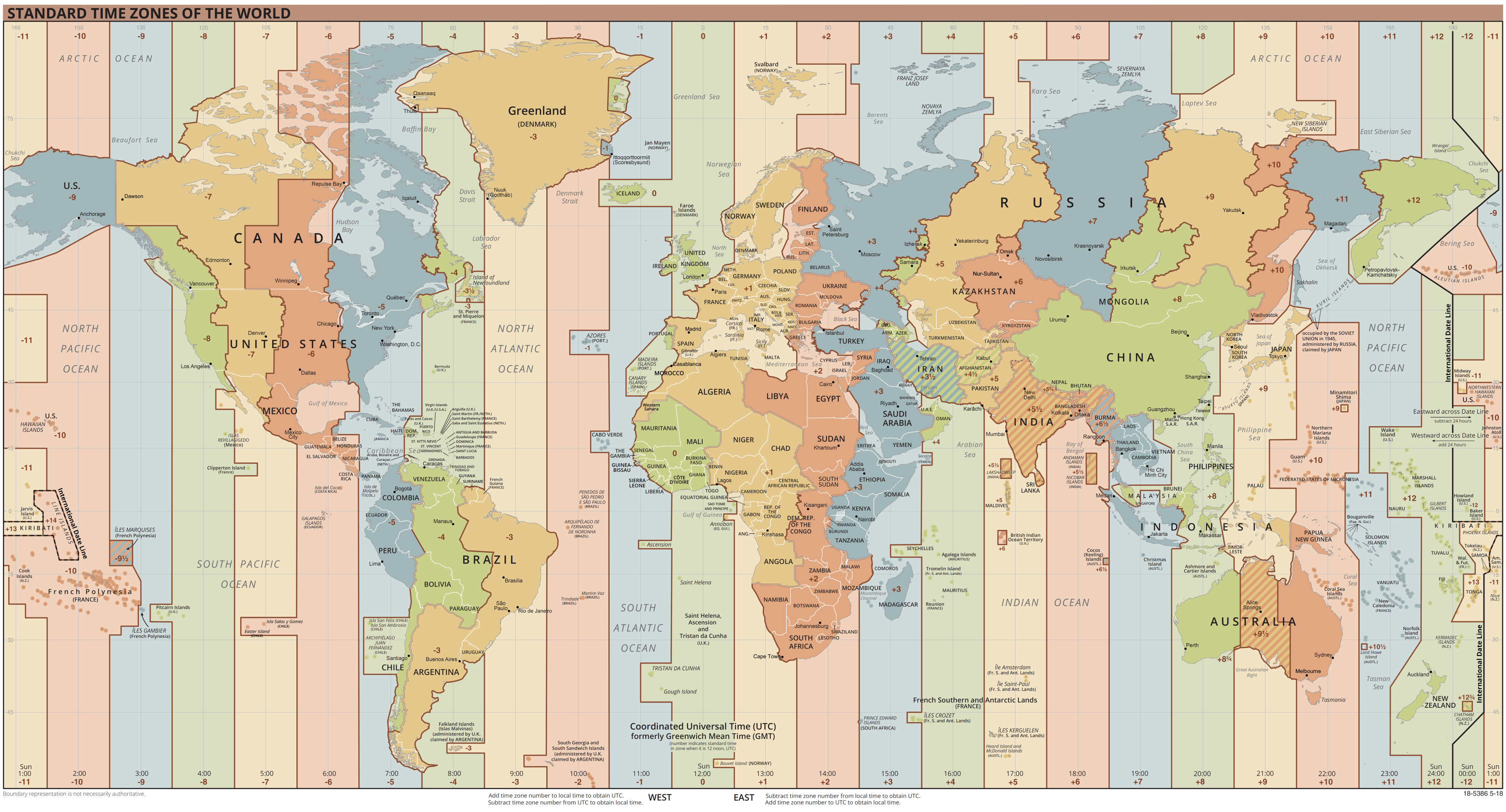
When programming a single page application, especially if it is designed to
run within different time zones, you often use UTC on the REST interfaces to
the backend and let the single page application handle the time zone
calculation.
When I first tried to implement this in Elm, I first tried to do this using
the tools at hand when using the standard package for time handling: elm/time:
On the start-up of my SPA I send a Cmd to the Elm runtime, requesting that it
generated a SetTimezone event with the local time zone of the user (here).
getTimezone : Cmd Msg
getTimezone =
Task.perform SetTimezone Time.here
When we give the Elm architecture this command, we get back this message:
type Msg
= SetTimezone Time.Zone
Then I stored the provided Zone in my model and used it within a helper
function to format timestamps:
formatTime : Zone -> Posix -> String
formatTime zone timestamp =
let
hour =
toHour zone timestamp
minute =
toMinute zone timestamp
in
(padLeft 2 '0' <| fromInt hour) ++ ":" ++ (padLeft 2 '0' <| fromInt minute)
formatTimeOfIsoTimestamp : Zone -> String -> String
formatTimeOfIsoTimestamp zone isoTimestamp =
toTime isoTimestamp |> Result.map (formatTime zone) |> Result.withDefault isoTimestamp
The problem with this approach is, that actually here does not tell the user's
actual time zone, that would take into account the shifts between standard time
and daylight saving time, but just something generic for the current offset to
UTC. So the
time zone we get will never be Europe/Berlin but Etc/GMT+1 or Etc/GMT+2
depending on whether we currently have standard time or daylight saving time.
The problem with that is, that you can display “current” timestamps with that
zone, but it fails for example as soon as you try to show timestamps within the
winter while it is still summer.
The solution to this is to use the functionality of justinmimbs/timezone-data.
Instead of using the here Task as in the code above, this Elm package
provides a different task, to get the time zone of the web browser the
application is running in:
getZone
The function, that generates the Cmd to request the time zone gets this:
getTimezone : Cmd Msg
getTimezone =
Task.attempt SetTimezone TimeZone.getZone
With this change, also the definition of the SetTimezone message changes a
bit as the retrieval of the time zone may fail:
type Msg
= SetTimezone (Result TimeZone.Error ( String, Time.Zone ))
When we handle the SetTimezone message we can unwrap this result and
use a default zone, if the correct zone couldn't be determined:
update : Msg -> Model -> ( Model, Cmd Msg )
update msg model =
case ( msg, model ) of
( SetTimezone result ) ->
let
zone = case result of
Ok ( _, timezone ) ->
timezone
_ ->
TimeZone.europe__berlin()
in

This is the first book on Haskell, that really made me want to read it.
I had it with me as an e-book on my vacations. I couldn't stop reading
it before I finished. It is a very good introduction to the basics of
the Haskell programming language. It even contains an understandable
explanation of the infamous monads. (Side note: they are a very simple
concept, and you shouldn't fear them.)
For me this book was the right amount of introduction to get me started.
Everything else I think I will be able to learn while using the language.
The book is available in print at your preferred book shop, or
can be read online and free of charge.
Links to resources

I like the books from O'Reilly. For many years I've seen the ad on the
backside advertising Safari. Sure, I checked out what this is, but I
wasn't really interested to have a digital copy for a limited amount of time.
I already had the print version.
I love to read real books made of paper. I use highlighters and add
notes, while reading. I make the book mine. And after finishing the book, I can
place it on my bookshelf, to show the books I like to others. This doesn't work
with my Tolino e-book reader. While I have this device,
I still buy most books as a paper copy.
Some days ago, I heard of Safari again on a podcast. I thought, that at least I
should check it out. It's not only O'Reilly books anymore and it includes videos
and other podcasts as well. There is a free 10 days trial, so I did not have to
invest more than some of my time.
weiterlesen | read more | lee mas | lê mais | 閱讀更多 »

RxJava is an implementation of “Reactive Extensions” (Rx) in Java. But what is
this? Originally Rx are an implementation of Microsoft to address the
increasing complexity of software. It is a model to build large scale
asynchronous service architectures.
Another company that has to be mentioned is Netflix: they implemented the
Rx in Java which resulted in RxJava.
On the programming side Rx looks very similar to how streams
(java.util.stream.Stream) work. The main difference in my opinion is that
streams are pull and lazy. They produce only as much data as someone is reading
from them. RxJava on the other side is more push style. The source of data is
pushing events through a pipe of operators similar to what you know from streams
(filter(), map(), and so on) to the sink. And as I know from this book, Java
streams are the wrong tool to parallelize anything that is not CPU bound–like
network requests. There reason for this is, that (parallel) streams are executed
on a thread pool that is shared with several other features of Java. This thread
pools is limited to have only that many workers as the system has CPU
cores. Therefore this pool gets exhausted very soon, when threads in it get
blocked by I/O operations. Any thread waiting for an I/O operation effectively
results in a processor core not used by your program.
RxJava on the other hand is not limited to a fixed thread pool. Any source
(Observable) and sink (Subscriber) of data can be bound declaratively to
user defined Schedulers. As well as Rx favours a model in which I/O
operations are done asynchronously and non-blocking. Therefore resulting in a
need for much fewer threads. In a traditional model of using one thread per
network connection, threads become very soon the first thing that limits
scalability.
What is really great about this book
The best part of this book for me were the reflections on Relational Database
Access in chapter 5. While as a developer you might be tempted to convert
everything to the reactive model, this part of the book shows where it doesn't
make sense to do so.
By converting the access to your relational database to an asynchronous model
you won't gain anything. Whatever you are doing on the client side, let's say
for example your PostgreSQL will run all of your concurrent requests in
different processes. This results in a noticeable limit on the number of
parallel queries you're able to run. You cannot lift this limit by becoming
asynchronous on the client side.
Links to the book

ZooKeeper is a component that facilitates building distributed applications.
It is:
- a distributed hierarchical key value store,
- chooses C(onsistency) and A(availability) in the CAP theorem,
- works best on read-dominated workloads (< 10% writes),
- keeps content in the memory of each instance, and
- expects the data stored on each node (key) to be small (maybe several KiB).
The data managed by ZooKeeper is presented in a file system like manner with
directories and files whose names get separated by slashes (/). The difference
to a file system is, that you can store information in the directories as well.
Or seen differently: directories are files at the same time. Based on this
simple abstraction, users of ZooKeeper can implement things like leader election
in a cluster of software instances.
weiterlesen | read more | lee mas | lê mais | 閱讀更多 »

To stay on the right track with microservices, I wanted to revisit the
philosophy and organizational recomendations on how to do them right. After
reading Building Microservices in april this year, I
got Microservice Architecture, aligning principles, practices, and culture by
Irakli Nadareishvili et al.; O'Reilly Media, Inc., 2016.
The book can be read on one week-end as the content is very well condensed to
118 pages.
weiterlesen | read more | lee mas | lê mais | 閱讀更多 »

It's hard to find sources how to do front-end micro-services in a single page
application (SPA). Having a single front-end that faces the user
makes it hard to impossible to exploid the full power of going micro-services in
the back-end. For every new function you cannot just deploy the corresponding
service, but you have the dependency to update and redeploy the service as well.
So I was looking around how to go micro in an SPA. One of the ideas
I found on the web was to do so using web components. To evaluate this idea as
someone working mainly on the backend I thought I should get some literature and
bought the book Developing Web Components by Jarrod Overson and Jason Strimpel,
O'Reilly Media, Inc., 2015.
weiterlesen | read more | lee mas | lê mais | 閱讀更多 »
For several years now WhatsApp is spreading on the smart phones of my
contacts. Of course my friends are asking me to install the software as well.
But I hate using a proprietary service if there are open alternatives. This open
and comprehensive alternative was and is Jabber respectively XMPP (two names for
the same thing).
But this is nothing more then a protocol. Especially nothing anybody could
use. What a Jabber user needs is software and a service provider. Until now my
recommendation for both was Google Talk. The software perfectly integrated and
pre-installed on every Android phone. An easy to use user interface,
comprehensible to John Doe. Nothing made for freaks by nerds. And as an operator
Google provided a rock solid service.
That was a smasher: you could get everything well co-ordinated from Google,
you could chat with users of other providers, and you could even operate our own
server if you wanted to. Real class!
With my denial of using a closed system and my continuing referral to free
alternatives, I brought several contacts to Google Talk.
weiterlesen | read more | lee mas | lê mais | 閱讀更多 »
PGP-signed version of this history.
| KeyID |
Fingerprint |
Date |
Expires (sign/encrypt) |
Status |
|---|
| 70D6C898 |
CAEC A12D CE23 37A6 6DFD 17B0 7AC7 631D 70D6 C898 |
2006-08-10 |
2010-01-01/2010-01-01 |
This is my main GPG key since 2006-08-10. |
| C9CD24F7 |
85A0 801A 2392 424F 69AB 5A63 C6D6 197D C9CD 24F7 |
2003-03-06 |
2008-03-04/2008-03-04 |
Key in use for special purposes. Please don't use it for
e-mail. |
| 4E59C7E6 |
B0F5 9D8C 28A8 34B6 FDE1 410A 3D27 3DDA 4E59 C7E6 |
2003-01-21 |
2007-01-01/2006-01-01 |
Key still exists, but only used for migration-signing to new key
anymore. |
| 8D8B4A2E |
6F81 B414 B8A1 1806 A333 A18E 0142 F366 8D8B 4A2E |
2001-01-11 |
*** revoked *** |
Public and private key still exist, never used for e-mail/not used
anymore |
| AA839AF9 |
85E8 0EE5 C852 363C FC19 BD5F 27FE 6356 AA83 9AF9 |
2000-03-06 |
*** revoked *** |
Public and private key still exist, but not used anymore. |
| 034FDE2A |
EA16 DEA8 4146 12EE 3B56 68D8 0A70 794E 034F DE2A |
1999-09-15 |
*** revoked *** |
Public and private key still exist. |
| 55DB8129 |
AF 14 32 B5 69 38 30 6E 3A B8 13 8D 66 A8 66 AE |
1999-04-27 |
never :-( |
Lost private key! |
| B3D1AF25 |
8C 79 81 AA ED 95 4D 0B 8F 53 09 52 9A 39 32 49 |
1998-05-25 |
*** revoked *** |
Public and private key still exist, revoked because e-mail address
is not used anymore. |
| 730BD791 |
??? |
1997-07-05 |
never |
Lost public key, private key still exists. |
| D9954A11 |
??? |
1996-10-23 |
never |
Lost public key, private key still exists. |
| 3336E4E9 |
??? |
1996-07-24 |
never |
Shared key (for the sysops of my former mailbox), I am not the only
one that has the private key. Public key lost. |
| 8B674F75 |
DE 51 C1 7E E4 99 4B 9D 5B 76 06 B2 DF 00 64 F1 |
1996-07-18 |
*** revoked *** |
Public and private key still exist, revoked because e-mail address
is not used anymore. |
There exist some even older keys that I have never used in the internet
and that only contain FidoNet addresses. These keys are completely lost.
I neither have the public nor the private keys anymore.
Change history
2006-08-10: Marked key AA839AF9 as revoked, updated signing-expire-date for key
4E59C7E6, added new key 70D6C898
2003-12-04: Updated expiry information for 4e59c7e6
In 2000, IM Unified announced to create a protocol that enables an instant
messaging client to join different IM services. Founding members were MSN,
Odigo, Yahoo! and others.
Since then I have not heard much of IMU. I don't even think that their IMIP
protocol will ever be used really. But it does exist and e.g. the Yahoo!
messenger client supports it. You only have to change some values in the Windows
registry. Afterwards, you're client is able to join other IM services like
Odigo with the Y! messenger.
For no other reason than to see how IMIP works I've dumped some IMIP sessions
with a network sniffer. The IMIP protocol is very simple structured and looks a
bit like SMTP or http.
All data is exchanged over a TCP/IP connection. The clients connects to port
11319 at the server. Firstly, it performs the login handshake and afterswards,
it is exchanging messages, presences and other data. All data is exchanged in
blocks.
All blocks have a structure of lines. Every line is finished by \r\n (carriage
return, line feed). The first line contains the type of a block, the second line
contains the size of the block (first two lines not counted). It is a decimal
ASCII number containing the size in bytes. Starting at the third line, there are
head lines, optionally followed by an empty line, optionally followed by a block
body. If the body is empty, the empty line can be absent. (The Y! messenger is
allways sending the empty line, the Odigo server isn't.)
weiterlesen | read more | lee mas | lê mais | 閱讀更多 »
